Today we’re launching… well, beta-launching, a new Android Emulator-as-a-service, for your CI jobs. Say hello to Eaase.dev.
Unlike the other Emulator services, we have the easiest interface with the remote emulator: we just give you an ADB connection so you can do whatever you want with it.
But why?
There are quite a few emulator services out there, the one you’re probably most familiar with being Firebase Test Lab (or, Gradle Managed Devices). These services are not technically an emulator as a service, they’re more like a test-runner as a service. They take an APK, run the tests, and send back the results.
This has some advantages: for example, Marathon Labs is a similar service, but since it has access to the APK it can do things like test-sharding or re-running flaky tests.
But each of these services have their own non-standard API to interact with them. This means that there are many Gradle plugins out there that won’t work with them. In particular, we at Screenshotbot care about screenshot testing: and most of the Android screenshot testing libraries don’t support even Gradle Managed Devices.
We wanted an emulator-as-a-service that can help our customers with their Screenshot testing infrastructure, and that’s how we got here.
Give it a try
Eaase is in Beta. For now, we’re keeping the service absolutely free, for reasonable use. If you sign up now, we’ll also waive any monthly fees on your account forever. We expect to fully launch in a few months.
First, sign up and create an API Token, export it as follows:
export EAASE_API_TOKEN=...Now, we need to download the eaase client:
curl https://cdn.eaase.dev/installer.sh | sh (Ping me if you want the Windows binaries.)
Now, you can check-out an emulator and run arbitrary command on it:
$ ~/eaase/eaase run -- adb shell ls
acct
adb_keys
apex
bin
...
vendor
$What just happened here: we checked out an emulator, ran the command and then discarded the emulator. If you have an Android project lying around, try running your androidTests via Eaase:
$ ~/eaase/eaase run -- ./gradlew :connectedDebugAndroidTests
...
If you want to try screenshot testing, here’s a sample app that uses Shot. You can record or verify screenshot tests using Eaase:
$ ~/eaase/eaase run -- ./gradlew :executeScreenshotTestsIn particular, this last command will require more complex ADB commands that other Emulator services won’t be able to provide.. or at least, not easily. (It can be done with Firebase Test Lab, but it’s super convoluted, and you’ll spend a lot of time testing the integration.)
Some screenshot tests will also require you to enable the hidden_api_policy. This is also something that couldn’t be done with Firebase Test Lab, but is easy to do if you have an ADB connection with Eaase.
Performance
Currently we’re seeing 15-20s boot times for emulators, which we think is not bad. But we want to get to zero-second boot times (i.e. by keeping emulators ready for you as soon as you request it).
Security
All the ADB connections are tunneled over an encrypted channel. Our company is also in the process of getting SOC 2 Type II certification We are SOC 2 Type II compliant as of today, soon after I posted this blog post. I’ll post a formal blog post announcing this soon.
Reliability
Each time we start up an emulator, we run a bunch of sanity checks on it to make sure it’s in a healthy state before sending it over to you. So you can be confident that the emulator you get is reliable for your CI jobs.
Pricing
As mentioned, this is currently completely free (for reasonable use). Once we fully launch, we expect to charge about $10 a month, plus $0.01 per minute of emulator use. If you sign-up now and try out an emulator, we’ll waive the monthly fee forever, so you only have to pay for what you use.
Open Source
If you’re familiar with our work, then you’ll know we love open-source. We plan to open-source Eaase along with our full launch. If we open-source it too soon, it’ll slow down our ability to make significant architectural changes, which is why we aren’t doing it yet.
What works and doesn’t work
As I mentioned, this is in public Beta. As a company, we like getting early feedback, and we encourage you to give us any or all feedback, good or bad, even if your thoughts are half-baked. (Sometimes the half-baked feedback is the most valuable, because it gives us a lot of insight into how people think about our product.)
Here’s what to expect, and the future work we expect to do:
- Capacity: we’re currently running on limited capacity of worker nodes. If we’re full, you might wait to get an emulator.
- We have only one emulator configuration at the moment. An API Level 30 emulator. We’ll make this configurable in the very near future.
- We plan to provide access to logcats from within our dashboard, but currently you can still generate logcats as artifacts using ADB during your CI jobs.
- We also plan to enable WebRTC so that emulators can be accessed and used for development purposes which still having access to the ADB connection.
- We plan to make it even easier to run multiple commands against a single checked-out emulator. For this, we’ll create an
eaase connectcommand that connect and daemonized the Eaase process so you can run commands after the connection. For instance a CI job might look like this:
~/eaase/eaase connect
adb shell set global ...
./gradlew :... And that’s all for now, please send your feedback to me. As always, if you’re looking to improve your screenshot testing infrastructure and would just like to talk about Screenshotbot, please reach out to me at arnold@screenshotbot.io.

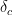 be the number of changes in commit
be the number of changes in commit  . Let
. Let  be the total number of unique images uploaded across all the commits, then it’s easy to see that:
be the total number of unique images uploaded across all the commits, then it’s easy to see that: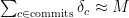
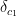 and
and 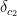 , should we cache the intermediate state of
, should we cache the intermediate state of  ? But that would mean storing the full map for
? But that would mean storing the full map for  … It might be possible to make this work, but as a small team we like simple solutions that are easy to maintain and debug. This isn’t it.
… It might be possible to make this work, but as a small team we like simple solutions that are easy to maintain and debug. This isn’t it. operation, but does not modify the old copy of the map and instead just returns a new copy. Internally, a functional map uses a special form of binary search trees. In particular, an
operation, but does not modify the old copy of the map and instead just returns a new copy. Internally, a functional map uses a special form of binary search trees. In particular, an 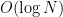 operation means at most
operation means at most 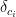 over the functional map for
over the functional map for  , the cost of the operation (in terms of time complexity and additional memory) is
, the cost of the operation (in terms of time complexity and additional memory) is 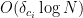 (where
(where  is the number of screenshots per commit). Over the entire repository this will be
is the number of screenshots per commit). Over the entire repository this will be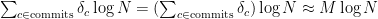
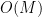 , and this only adds a
, and this only adds a 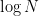 factor. This will scale ridiculously well, even if it’s all hosted on a single machine. Even for a mono-repo.
factor. This will scale ridiculously well, even if it’s all hosted on a single machine. Even for a mono-repo. last known maps, and pick a parent map that creates the lowest cost for us.
last known maps, and pick a parent map that creates the lowest cost for us.