Introduction
At the heart of Screenshotbot, is a mapping from Git commits to a list of screenshots.
Around this simple mapping, we build powerful workflows and interactions. How do we implement such a mapping?
Before we begin, let’s formally define this requirement. For the sake of this blog post, we’ll look at a simplified version of what Screenshotbot actually does.
The list of screenshots we mentioned earlier is actually a map from a name->image (or in Java: Map<String, File>). But we need to store one such map for every commit, so this needs to look like commit->(name->image) (or in Java: Map<String, Map<String, File>>).
We need to figure out how to efficiently store this. We have some specific querying requirements, but I think we can just focus on the storage considerations for this blog post.
A naive solution
There’s an obvious first approach, and it’s actually the one we initially built into Screenshotbot. For each commit we just store the full map. If you come from a relational database world, you can think of this as a table with columns COMMIT, NAME, and FILE, with an index on COMMIT and NAME.
This naive solution is not bad, and will indeed get you quite far. In fact, this was the schema I used even at Facebook when I built the screenshot testing infrastructure there. (I’ve talked a bit about this in my Droidcon talk.)
And at Facebook this worked well … until we tried to build a feature where we commented on every diff with the screenshot changes. That’s when our database came to a crawl. We never solved this at Facebook, at least during my time there.
The scaling issue
The problem is that for a large company like Facebook, especially one that uses a mono-repo, you’re going to have thousands of commits every day.
And you could potentially have tens of thousands of screenshots. The database with this schema is growing at a rate of 10,000,000 rows per day. This is just not scalable without some massively distributed architecture.
But a massively distributed architecture adds a significant operational overhead. It also feels … overkill.
Consider this: most of those commits in the mono-repo aren’t really changing screenshots. Most of the rows we’re storing are redundant. This gets us to our first optimization: Add an extra layer of indirection.
In relational database terms, we could have a screenshot_map table, with an ID, NAME, and FILE. And each commit will point to a specific screenshot_map‘s ID. You will need to store some hashes for each screenshot_map in a separate table, in order to query for duplicates. This will remove a huge chunk of those redundant rows.
It also helps that in a large mono-repo screenshots are usually broken up into multiple product verticals: what Screenshotbot calls channels. This makes it more likely that some of the mappings will stay unchanged for longer periods of time. But this relies on the end-user being well-behaved and proactively trying to break up screenshots into channels.
So this solution combined with a well-behaved user, is actually not that bad. You’ll get quite far with this. And at Screenshotbot, it got us quite far for a few years. But eventually this wasn’t good enough.
It turns out we do have some large channels. And it turns out that some of our largest channels also has flaky screenshots. Screenshotbot provides tooling to support flakiness, so we need to be able to handle flakiness without scaling issues. But flaky screenshots will cause new screenshot_maps to be created each time even if a single screenshot is flaky. This is not good.
Heuristics
This leads to our second insight: even if screenshots change, in most cases only a few screenshots are actually changing. Let 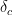


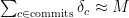
It’s possible that there are a few duplicates: for instance, for a revert commit, the
And
This leads to an obvious heuristic: Perhaps we can just store the deltas? Progress! but there are a whole lot of edge-cases to consider. We have to replay the deltas to generate the map, how do we do that efficiently? How do we pick which previous map to take the delta from? If we replay 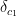
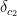


Functional collections
Enter functional collections.
If you’re coming from a functional programming language, this will not be new to you. If you’ve mostly been working with Java, Kotlin or the like: prepare to have your mind blown.
A functional map is like an Immutable map, but with better complexity guarantees. In particular, inserting an element to functional map is a 
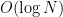
(For an intuition of how this works, consider two large binary search trees that differ in just a few values. A large number of sub-trees in the two trees could be identical and the two trees could potentially share the same nodes between them.)
See where we’re going with this?
If we apply the 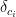

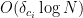

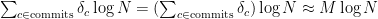
That is not bad! We already had an unavoidable need to scale with 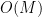
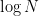
(We add an extra optimization here to break up the “chain” of deltas, so in order to compute the map of the most latest commit, you don’t have to apply deltas from the beginning of time. In practice, this means most of the maps aren’t computed, and we would actually be scaling like
We still have to address how we choose which commit to compute our deltas against. We use some heuristics here, but using functional maps makes it easier to run these heuristics efficiently. Essentially we look at some 
What does this mean for you?
In particular, this means that even our open-source version will scale pretty well for you, even when hosted on a single server.
But what about databases?
You might wonder what the schema for this looks like. Some of these operations that I described seem like it will have to hit a database multiple times (e.g. walking up a graph of parent maps), and that seems slow. And the answer is: we just don’t use a database. Everything is stored in memory. But that’s a blog post for another time.
Coming soon
In our future posts, we’ll also cover our image processing primitives, and how we’re able to efficiently provide features like Zoom to Change and Masks. We’ll cover how we handle high availability, and talk about some of the other popular open-source libraries we’ve built over time to support Screenshotbot.
Finally, here’s a link to our code that handles screenshot-maps.
